Blog
Trouver la bonne association à l’aide du data mining/machine learning
Ce billet vous propose de découvrir l’intérêt des méthodes du data mining et du machine learning dans le contexte des activités d’un webmaster.
Nous allons utiliser une technique d’association sur un dataset spécifique, avec une application très concrète en tête. Les techniques d’association ont pour objectif de déterminer l’affinité entre des objets. La plupart du temps, on peut résumer les résultats d’une association de manière très simple, en annonçant qu’un objet, par exemple un casque, est souvent utilisé de concert avec un autre objet, par exemple ici une moto.
L’intérêt de ce type de méthode est assez vite évident, avec notamment des applications directes en recommandation de produits (“les clients qui ont acheté des bananes ont aussi acheté des petits suisses Malo”, la preuve), en recommandation de contenu (“les lecteurs qui ont apprécié cet article ont aussi lu l’article sur les meilleurs sushi bars de Clermond-Ferrand”) mais aussi dans des domaines moins connus comme par exemple la médecine (pour prédire le risque de développer certaines maladies).
L’application qui va nous guider ici est très différente. Imaginons que j’ai sous la main un dataset avec des recettes de cuisine. Il y a plusieurs choses que je peux faire assez facilement, comme notamment proposer à une personne les recettes qu’elle peut réaliser avec ce qu’elle a dans sa cuisine, je peux également lui dire ce qu’il faut acheter au minimum pour réaliser une recette. Mais il y a un problème beaucoup plus amusant : que dois-je lui conseiller d’acheter pour compléter le contenu de sa cuisine, en vue de permettre à cette personne d’avoir le plus grand choix de recettes possible. Si je reformule ce problème, ce que je veux c’est la liste des produits que vous avez chez vous, et je vais vous dire d’acheter tel ou tel chose en plus, de telle manière à avoir une cuisine “la plus complète possible”.
Coup de bol, j’ai justement sous la main un dataset avec plein de recettes, et les ingrédients qui les composent. Le dataset est composé de 13 000 recettes du site epicurious qui sont classées par type de cuisine (italienne, asiatique, etc.). Il s’agit d’un dataset anonymisé, qui ne contient que les ingrédients qui composent chaque recette. Pour ce billet, j’ai utilisé les 268 recettes de cuisine française qui sont dans le dataset.
Une ligne typique du dataset correspond à une recette, en voici un exemple :
butter coffee wheat starch cocoa cognac egg milk cream
Pour travailler efficacement, j’ai utilisé R. R est un langage de programmation et un environnement de travail utilisé pour un très grand nombre de tâches dont des analyses statistiques de données, ou encore la création de visualisations graphiques. R est open source et possède aujourd’hui une communauté particulièrement dynamique qui contribue à son développement.
Pour installer R, rien de compliqué, il suffit de télécharger l’archive qui convient à votre système d’exploitation. Pour se servir de R, il existe deux modes de fonctionnement : en ligne de commande (mode interactif) ou en écrivant ces commandes dans des fichiers qui seront interprétés ensuite (scripts). R est un système très riche qui possède de nombreuses fonctionnalités, notamment grâce à son système de packages. Un package est tout simplement une bibliothèque de fonctions utiles, créées par l’équipe de développement de R ou par des tiers. Pour installer un package, on peut passer via l’interface graphique ou via la commande install.packages. Vous pourrez ensuite utiliser le package en le chargeant via la commande library().
Pour proposer des ingrédients “utiles” je vais donc utiliser une technique d’association, que vous pouvez trouver dans le package arules. Je vais donc tout d’abord charger les packages arules et arulesViz (qui permet de visualiser les règles d’association).
> library(arules)
> library(arulesViz)
Deuxième opération, charger le dataset:
> datarec <- read.transactions(“recipes.csv”, format=”basket”, sep = “;”)
Pour vérifier que tout est OK, je peux rapidement tracer un histogramme montrant les fréquences d’utilisation des ingrédients dans les recettes.
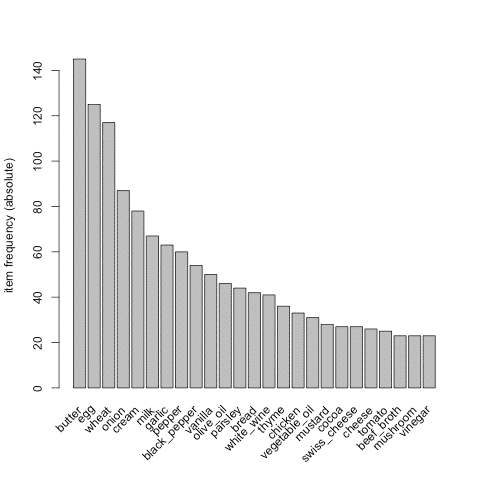
Sans trop de surprise, l’ingrédient star de la cuisine à la française est le beurre^^ puis les oeufs, le blé (en fait la farine de blé), les oignons, etc. Il faut savoir que sur epicurious, les recettes “française” sont assez étonnantes…
Une fois que j’en suis là, et bien le travail est presque fini car pour utiliser l’algorithme d’association, une seule ligne de R suffit:
> rules <- apriori(datarec, parameter = list(supp = 0.01, conf = 0.5,minlen=3))
Ici je viens de créer les associations d’au moins 3 ingrédients. Je peux afficher les associations avec la commande inspect().
lhs rhs support confidence lift
31 {cinnamon,ginger} => {pumpkin} 0.011 0.75 67.00
32 {ginger,pumpkin} => {cream} 0.011 1.00 3.44
532 {olive_oil,saffron} => {tomato} 0.015 0.80 8.58
533 {saffron,tomato} => {pepper} 0.011 0.75 3.35
9551 {black_pepper,mushroom,olive_oil,onion} => {garlic} 0.011 1.00 4.25
9552 {garlic,mushroom,olive_oil,onion} => {black_pepper} 0.011 0.60 2.98
9553 {black_pepper,garlic,mushroom,onion} => {olive_oil} 0.011 0.75 4.37
Au dessus on voit un extrait du résultat, avec quelques règles d’association divers. On voit ainsi (ligne 533) qu’au couple safran + tomate est associé le poivre, avec un support de 0,011, une confiance de 0,75 et un lift de 3,35. Le support, c’est la proportion de recettes qui utilisent les trois ingrédients. La confiance c’est la proportion de recettes qui utilisent du poivre parmi celles qui utilisent safran et tomate. Enfin, le lift est une quantité plus complexe : c’est l’amélioration du résultat apportée par le choix du poivre par rapport au choix d’un troisième ingrédient au hasard quand on a déjà du safran et des tomates.
On peut également représenter graphiquement les règles, par exemple ici j’ai tracé les 19 premières règles d’association à 4 ingrédients.
> rules <- apriori(datarec, parameter = list(supp = 0.01, conf = 0.2,minlen=4))
> plot (rules[1:19],method=”graph”,shading=”confidence”)
Mais la lecture graphique est plus compliquée au final que la lecture sur le format texte.
Une fois tout ceci posé, comment faire une proposition de choix d’ingrédients concrète pour un internaute ? Première chose, on lui demande de nous dire ce qu’il a chez lui. Par exemple, j’ai chez moi en ce moment du poulet, du poivre et de l’ail. En utilisant intensivement les commandes vues plus haut avec des opérations de sélection des règles, du type qui suit :
> rules <- apriori (datarec, parameter=list (supp=0.01,conf = 0.15,maxlen=4))
> rules.sub <- subset(rules, subset = lhs %in% c(“garlic”, “pepper”,”chicken”) & !rhs %in% c(“garlic”, “pepper”,”chicken”) & lift > 2)
> rules.sub <- sort (rules.sub, decreasing=TRUE,by=”lift”)
On va obtenir des règles concernant uniquement les ingrédients que l’on possèdent :
lhs rhs support confidence lift
11117 {chicken,garlic,pepper} => {white_wine} 0.011 0.75 4.9
11176 {chicken,garlic,pepper} => {black_pepper} 0.011 0.75 3.7
11191 {chicken,garlic,pepper} => {cream} 0.011 0.75 2.6
463 {chicken} => {ham} 0.045 0.36 5.73
670 {pepper} => {lemon_juice} 0.034 0.15 2.01
681 {chicken} => {chicken_broth} 0.022 0.18 2.56
692 {pepper} => {chicken_broth} 0.034 0.15 2.12
723 {chicken} => {swiss_cheese} 0.041 0.33 3.31
768 {chicken} => {mushroom} 0.022 0.18 2.12
782 {garlic} => {mushroom} 0.056 0.24 2.77
849 {garlic} => {bay} 0.041 0.17 2.13
1649 {garlic,pepper} => {mussel} 0.015 0.17 7.77
Il faut ensuite choisir ce que l’on va proposer. La métrique clé est ici la confiance, car la confiance va indiquer si on peut faire beaucoup de nouvelles recettes avec le nouvel ingrédient. En arbitrage à confiance égale on utilisera le lift, qui nous donnera l’amélioration. Ici on va donc proposer en priorité à la personne d’acheter du vin blanc, du poivre noir puis de la crème. Il faut bien sûr vérifier à chaque étape que cela permet de faire réellement une recette, sinon il faut refaire le calcul avec le nouvel ingrédient potentiel, pour proposer des achats de groupes d’ingrédients. On pourrait faire directement les calculs sur des groupes, mais cela deviendrait compliqué en terme d’explications pour un simple billet de blog 😉
Voilà, vous savez maintenant comment réaliser un outil qui permet de vous proposer les meilleurs ingrédients pour votre cuisine 😉
Si vous pensez que ces méthodes ont du potentiel, si vous voulez mettre le même type de chose en place, n’hésitez pas à venir à notre formation “Webmarketing, comprendre et utiliser le machine learning” pour comprendre les enjeux du machine learning pour le webmarketing, et pour être capable de mettre en place des outils similaires.