Blog
Prédire les rankings de Google : Vincent Terrasi vous dit comment faire
Vincent Terrasi est l’une des personnalités de la communauté SEO/data les plus prometteuses, et il nous a fait l’honneur de faire une billet invité sur son système de prédiction des rankings de Google. Je vous laisse découvrir sa prose…

Avant de commencer, un grand merci à Sylvain de me permettre d’intervenir sur son blog sur un sujet que j’ai présenté à OVH Summit 2016 : La prédiction de positions SEO.
Je me présente en 1 phrase : @vincentterrasi, je suis responsable du Data-Office OVH et je me définis surtout comme un Data-Scientist passionné par le SEO et le Marketing. J’ai rejoint depuis 3 mois OVH et je les remercie de me permettre de partager ces travaux en Open Source sur le github officiel.
Contexte
Une fois par an, je vois passer un article sur la prédiction de positions dans les résultats des moteurs de recherche. A chaque fois, les résultats annoncés sont relativement corrects mais impossible à vérifier car le code source n’est pas partagé.
Je me suis donc lancé le défi de refaire la même chose mais de partager les résultats et de le présenter à OVH Summit 2016. Avec Rémi Bacha, nous avons identifié un bon sujet : « du monitoring à la prédiction SEO ».
Suite à la lecture des articles traitant du sujet, j’ai vite compris qu’il sera difficile de prédire la position exacte car cela demande un jeu de donnée très important. Il faut en effet avoir en sa possession l’intégralité des résultats sur un grand nombre de requêtes.
Dès le départ, nous avons donc fait le choix de simplifier le problème en essayant de prédire si une page se trouve dans le top 10 pour une requête, ou pas. Il faut dire qu’être sur la seconde page, c’est être invisible.
Etape 1 : Création du dataset
Nous avons travaillé avec Ranxplorer, pour tester ce nouvel outil d’analyse de positions SEO, mais aussi et surtout car il possède un très grand volume de mots clés surveillés (plus de 100 millions). Ranxplorer nous a ainsi fourni très rapidement le top 100 sur plus de 2 000 mots clés autour de l’e-commerce « jardin ».
https://github.com/ovh/summit2016-RankingPredict/tree/master/ranxplorer
Etape 2 : Nettoyage du Dataset
Là, nous avons eu une surprise car environ 1% des données sont tout simplement inexploitables pour de nombreuses raisons. Nous avons donc retiré toutes les urls invalides pour les raisons suivantes :
- Crawl top lent
- Contenu non HTML
- Souci réseau
- Serveurs web trop lent
- Erreurs générées par le serveur
- URL redirigé définitivement en 301
- URL redirigé temporairement en 302
- Authentification demandée
- Page introuvable en 404
- Boucle infini !
Etape 3 : Construction du Dataset
Nous avons enrichi le dataset à partir des trois logiciels SEO suivants :
- Majestic SEO (qui permet de mesurer les facteurs externes)
- Screaming Frog (qui permet de mesurer les facteurs internes)
- Visiblis (qui permet de mesurer les facteurs sémantiques)
Pour Majestic SEO, j’ai utilisé l’API et vous avez accès à mon code source qui permet d’analyser chaque site.
Pour Visiblis, j’ai demandé l’aide de Jérome (le créateur de l’outil) car il était compliqué de faire les manipulations nécessaires à travers l’API en interrogeant plus de 190 000 urls. Jérôme a depuis mis dans son API une méthode qui permet d’interroger plusieurs urls à la fois. Enfin, concernant Screaming Frog, il suffit d’avoir une licence annuel (165€) pour crawler autant d’urls que l’on souhaite.
J’ai mis au point une fonction en R qui merge les données. C’est toujours la même et elle est détaillée dans le code R suivant :
https://github.com/ovh/summit2016-RankingPredict/blob/master/step2_mergeScreamingFrog.R#L15
Etape 4 : Normalisation & Training
L’étape de normalisation est essentielle pour utiliser l’algorithme, il est essentiel de borner toutes les valeurs autour du même intervalle pour ne pas favoriser certaines variables. En effet, nous avons des scores compris en 0 et 100 tandis que nous avons des nombres de liens compris entre 0 et plusieurs centaines de milliers. La normalisation permet d’avoir toutes les variables entre -1 et 1.
https://github.com/ovh/summit2016-RankingPredict/blob/master/step8_xgboost.R#L46
Ensuite la phase d’entrainement est primordiale pour éviter la sur-optimisation, c’est un procédé très employé en Machine Learning. Nous allons travailler avec 75% du dataset et vérifier nos résultats sur les 25% restants.
https://github.com/ovh/summit2016-RankingPredict/blob/master/step8_xgboost.R#L49
Etape 5 : Utilisation de XgBoost
L’algorithme utilisé pour l’apprentissage se nomme Xgboost, c’est un diminutif pour eXtreme Gradient Boosting package.
C’est une implémentation scalable et efficace du framework gradient boosting.
Elle se base sur deux grands concepts :
- Les arbres d’apprentissage
- La régression linéaire qui permet de choisir ou plutôt appliquer un facteur de boost sur les variables les plus importantes
Si vous souhaitez approfondir le sujet, c’est ici : https://github.com/dmlc/xgboost
Etape 6 : Optimisons les seuils
Pour la conférence, j’ai travaillé seulement avec quelques facteurs pour maintenir l’aspect pédagogique de mes slides.
Mais vous pouvez tester avec les facteurs de votre choix.
https://github.com/ovh/summit2016-RankingPredict/blob/master/step8_xgboost.R#L23
- Nombre de mots
- Temps de réponse
- TrustFlow
- CitationFlow
- Score sémantique du titre
- Score sémantique de la page
- …
Nous avons essayé de nombreuses combinaisons pour avoir le meilleur résultat possible.
Voici les variables que nous avons défini dans la fonction xgboost :
https://github.com/ovh/summit2016-RankingPredict/blob/master/step8_xgboost.R#L57
- data : il s’agit de notre dataset
- label : on lui indique les états pour chaque ligne : top10 ou non top10
- eta : échantillon que l’on conserve après chaque itération pour éviter la sur-optimisation
- nround : nombre d’itérations que l’algorithme doit accomplir
- max_depth : il s’agit de la profondeur maximal de l’arbre d’apprentissage ( ici : 10 )
- objective = binary:logistic : Nous indiquons à l’algorithme que nous travaillons avec la régression logistique pour faire une classification binaire ( top10 ou non top10)
Attention, l’algorithme va demander plusieurs minutes de calcul pour sortir les premiers résultats. Une fois ce calcul initial terminé, nous utilisons la fonction predict pour tester le modèle généré sur le jeu de test.
Etape 7 : Résultats
Nous générons la matrice de confusion suivante :
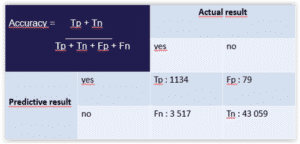
Vous remarquez, il y a des vrais positifs, des vrais négatifs, des faux positifs et des faux négatifs.
Un vrai positif est un résultat prédit comme Vrai et observé comme Vrai. Un vrai négatif est un résultat prédit comme Faux et observé comme Faux. Un faux positif est donc un résultat prédit comme Vrai et observé comme Faux.
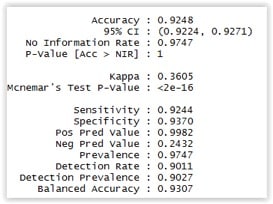
Je donne la formule mathématique correspondante à la notion en haut à gauche dans l’image. On observe une efficacité d’environ 92% sur ce dataset et ces facteurs. La méthode prédit la présence dans le top10 (ou non) avec une efficacité de 92% !
Détail pour les connaisseurs :
Nous pouvons tracer pour les spécialistes une courbe ROC avec la réparation de taux de vrai positifs par rapport au taux de faux positif. Plus la courbe s’éloigne de la diagonale, meilleure est le résultat.
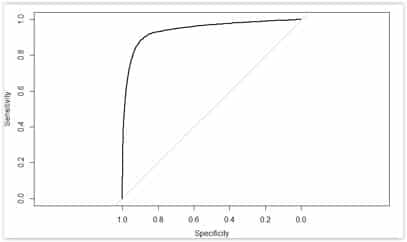
Les résultats restent relativement corrects.
Observons désormais les facteurs de ranking pour ce dataset français sur le domaine des abris de jardin.
Il vous suffit juste d’utiliser cette ligne de code :
https://github.com/ovh/summit2016-RankingPredict/blob/master/step8_xgboost.R#L77
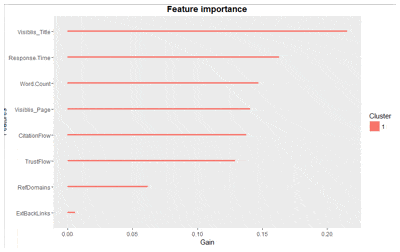
Concernant les facteurs de ranking qui sont retenus pour ce dataset autour des abris de jardin et en France (oui j’insiste mais c’est très important), je ne préfère pas faire de commentaires car encore une fois, la plus grosse erreur serait d’en tirer des conclusions générales.
Conclusion
Désormais, vous avez une méthodologie pour trouver vos propres facteurs et nous avons mis ce travail de recherche en open source car il est perfectible et nous comptons sur votre aide.
Cela m’aura pris plus de 11 soirées et le plus long aura été de construire le dataset : le plus important est de travailler avec des données de qualité.
Si, vous souhaitez tester le code source, c’est ici : https://github.com/ovh/summit2016-RankingPredict/
Si vous avez des questions sur ce projet pour l’utiliser, c’est ici : https://helpers.ovh.com/c/open-source
Encore un grand merci à Visiblis et Ranxplorer pour m’avoir aidé à enrichir le dataset.
Un grand merci à Olivier Nicols, DataScientist OVH et Sylvain Peyronnet, Chef des algorithmes pour avoir vérifié ce travail. Bien sûr, Sylvain m’a fait remarquer que les facteurs choisis sont discutables mais je vous invite à utiliser ceux que vous souhaitez.
De la même façon, il peut être très intéressant de travailler sur un dataset moins généraliste et de lancer cet algorithme sur des datasets spécialisés et tester avec des nouveaux facteurs comme AMP ou le type de certificat SSL ( EV, … )
Allez, je conclus sur un bébé loutre car je reste padawan des Frères Peyronnet :

Merci Vincent pour cet excellent et passionnant travail !